
HBase作为一个数据库,如何写入数据,读出数据,如何写日志,如何做快照,Region如何切分,数据结构是什么,在磁盘上又是如何存储,有二级索引吗?本文是一篇概览,适合新手,每个操作都很复杂,如果都详尽就需要一本书了。
读写流程
读写流程都依赖一个’hbase:meta’表,该表也存储在一个RS上,该表存储了集群中所有Region的信息,可以通过zk来查询该表的RegionServer位置。
以其中一张表’name:t2’来举例,在下方的’hbase:meata’表中,在除了第一行,其他的每一个rowkey都是一个Region的元数据。rowKey由(tableName,startRow,timestamp,encodeName(前3个字段产生的md5的hex值))拼接而成,比如name:t2,,1572571990517.0f0688ba5bcb156bc56220由于是第一个Region因此没有startRow,包含如下几列:
- info:regioninfo:存储了4个信息:encodeName,regionName,startRow,stopRow
- info:seqnumDuringOpen:Region打开时的sequenceID值
- info:server:对应的region的RS的地址
- info:serverstartcode:所在的RS启动时的timestamp
- info:sn
- info:state
客户端会缓存meta表的信息,当然,meta表的信息如果改变了,那么客户端访问对应的RS可能得到错误的结果,此时客户端会重新获取meta表的信息并缓存
1 | name:t2 column=table:state, timestamp=1572571991554, value=\x08\x00 |
为什么meta表存在一个Region上:meta表很小,不会被切分;当之后如果真的需要切分的时候,在加一层索引即可。
读写数据流程大概如下图: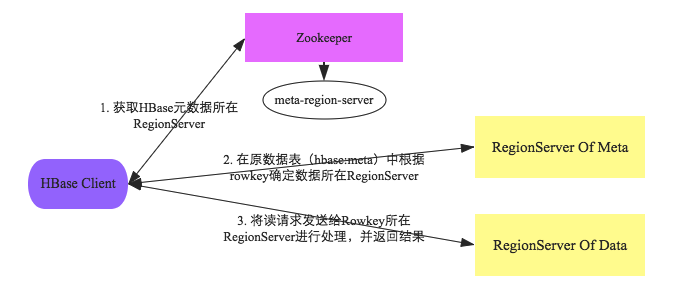
写数据流程
当我们使用shell或者其他api写入一条数据,比如put 'test','rowkey1','cf1:age','18',实际上我们是在与hbase的客户端进行交互,客户端会与HBase集群交互,最终得到数据。流程如下:
- 客户端获取
hbase:meta表的内容:先读本地缓存;如果本地缓存中的信息有误或者没有缓存内容,再与zk进行交互,查找hbase:meta表所在RegionServer的位置,然后获取表内容。这样做的好处是减少了zk的压力。 - 在进行put的时候,根据要写入的rowkey以及
hbase:meta表中的内容可以在info:server中找到管理该Region的RegionServer的地址 - 命令对应的RegionServer写数据,先将数据写入HLog,然后将数据写入对应的Region的对应的列簇的memStore,最后将memStore中的数据刷到hdfs上
Region写入阶段:
- 反序列化put对象,执行检查操作
- 获取行锁,获取当前系统的时间
- 将此操作编辑为一条WALEdit记录,sync写入HLog中
- 写入memstore
- 释放行锁
- 结束事务,修改对外可见
至此,写入结束,但是之后还有其他的流程,比如memstore太大了,就需要将内存中的数据写到hdfs上等。
HLog持久化等级
说道sync,类比MySQL的日志写入的级别(0,1,n),HBase中也有对应的级别来适应不同的业务场景:
- SKIP_WAL:不写Hlog,当然可能丢数据
- ASYNC_WAL:异步写入Hlog,也可能丢数据
- SYNC_WAL:同步写入文件系统,但是不一定就落盘了;注意:写入文件系统不等于持久化到了磁盘,因为文件系统也有缓存,这个缓存是内存,也就是如果操作系统崩了,依旧可能造成数据的丢失
- FSYNC_WAL:同步写入磁盘,最严格的等级
- USER_DEFAULT:用户没有指定,使用默认的等级SYNC_WAL
写入memstore
写内存是一个数据库为了提升写入效率必做的事情:
- 无论是在内存还是在HFile上,数据都是按照rowkey字符串升序排序的;为了能够保证有序且写入的速度,使用了
ConcurrentSkipListMap,类似redis中的有序集合(跳跃表+map) - 当内存不够了,会将数据刷到hdfs,见下节
- 刷内存的就是将内存中的对象写入到磁盘,那么这些对象也就没有了价值,会进行垃圾回收,这样会造成内存碎片。为了防止内存碎片,使用了
MemStore-Local Allocation Buffer(MSLAM):预先申请一个大的(2M)内存(Chunk),然后将对象写入这里面,如果满了,就新建Chunk。这样数据落盘后,gc之后剩下的碎片比较规整,也比较大,减少full gc。
memStore Flush
触发条件:
- memStore到达了一定的大小(memStore级别,Region级别,RS级别),可以通过配置参数修改阈值
- HLog数量达到了上限。
- 定期flush
- 手动flush
读流程
读流程比较复杂,因为可能会跨Region,而且更新数据和删除数据,都没有真正的删除,只是标记,比如标记的delete,所以还需要过滤。
整体流程:
- 与读数据的前两个流程一样
- 然后每个RegionServer会查数据,然后将数据返回
具体流程:
- 构造Scanner Iterator体系
每一个Region都有一个单独的查询逻辑:构造三层Scanner:RegionScanner,StoreScanner,MeMStoreScanner,StoreFileScanner
一个RegionScanner由多个StoreScanner,一个StoreScanner对应该Region的一个列簇
一个StoreScanner包含了MemstoreScanner和StoreFileScanner,对应内存和HFile
前两个Scanner都是调度而非真正的查,真正的查询会落在MeMStoreScanner和StoreFileScanner上。
分别查内存和文件,然后将结果合并,在查文件之前会查CacheBlock,如果存在对应的Block,就不用查文件,减少磁盘IO
- 淘汰一些Scanner
- 每个Scanner seek到startKey
- key-value构建最小堆
- 执行next函数进行过滤:
- 检查keyValue的KeyType是否是Deleted/DeletedColumn/DeleteFamily,如果是,跳过此Key列(列簇)
- 检查key-value的timestamp是否在范围,如果不是,忽略
- 执行其他的各种用户设置的filter
检查版本数是否满足设定的版本
如何过滤HFile
三种方式:KeyRange,TimeRange,布隆过滤器
- KeyRange:如果要查找的key不在此该HFile的范围,那么过滤
- 在StoreFile中有一个元数据[miniTimestamp,maxTimestamp],根据待查询的time条件过滤
- 布隆过滤器:布隆过滤器可以判断一个数据”一定不在“或者”可能存在“在该文件,系统会获取对应的布隆过滤器(每个Hile都有一个数组,就是布隆过滤器)加载到内存中,热点会缓存到内存
数据结构
整体上Hbase基于lsm树,这种树增加了写的效率,直接写内存;但是却降低了读的效率,读会访问很多的HFile。
Compaction
定义:多个HFile合并为一个
目的;
- 为了提高读效率,一般基于lsm的系统都会compaction,将多个file合并为一个文件
- 为了减轻namenode的压力,Hfile多了会造成namenode的压力增大,因此namenode会会存储文件的元数据信息;HFile多了会造成读数据的效率低下,因为读数据会访问多个HFile,会增加随机磁盘访问
- 删除过期的,超时的,超版本的数据
- 提高数据本地化率
分类
- minor Compaction:选取部分小的,相邻的HFile合并
- major Compation:将所有的HFile合并为一个大的,并且清除:被删除的,过期的,版本号超过的数据。这样做带来IO压力,网络带宽压力,而且读操作可能会超时。
触发时机
最常见的三种
- memstore flush,判断HFile是否超过了阈值
- 后台线程检查
- 手动触发
切分
读写操作都落到了Region上,因此如果一个Region太大,Region会进行切分,类似分表。
具体流程很复杂,简单流程如下
- 寻找分裂点,最大的store中的最大文件中心的一个Block的首个rowkey
- 分裂,修改‘hbase:meta’表,父Region下线,子Region上线。注意新的Region获得新的文件的时候是在Compaction阶段。
存储
存储分为内存和磁盘,memstore不再就是,就是一个跳跃表+Map。
blockCache
为了提高读性能,每一个RS有一个BlockCache,BlockCache也分为几种:
- LRUBlockCache:是一个lru,不过进行了改造,使用了分层缓存,将缓存分为single-asscess,multi-access,in-memory,分别占到了BlockCache的25%,50%,25%。这种做法可以更有效的缓存热点数据,防止一次冷查询将热点数据挤出内存,类似MySQL的(3/8-5/8)LRU;缺点:堆内的block会被淘汰,导致gc,甚至会导致full gc,为了解决它,实现了新的cache
- SlabCache:使用堆外内存,不建议使用
- BluckCache:三种模式:heap,offheap,file,分别对应堆内存,堆外内存,文件(最好是使用SSD之类的存储介质)。在启动时,会申请大量的bucket,默认为2M,每个bucket对应一个baseoffset,代表物理起始地址;每个bucket还有一个size标签,代表可以放入的block的大小,比如65K,代表可以放入64的block。如下图,图片来源于范欣欣博客

HFile
HFile是hbase文件在hdfs上的存储格式。所有的操作都离不开它的格式,正如程序=数据结构+算法,HFile就是数据结构,好的数据结构能够省下复杂的操作。
HFile分为v1,v2,v3。这里介绍v2
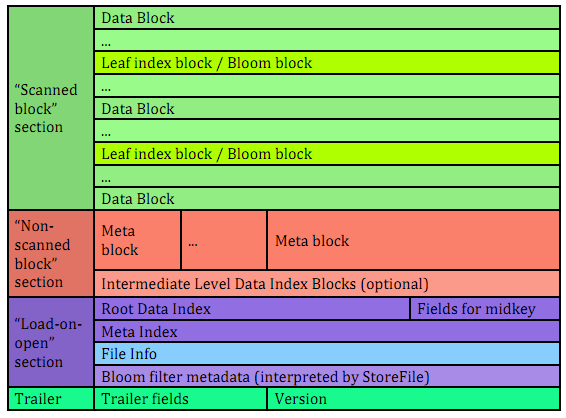
一个HFile可以分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section,Trailer
- Scanned block section:在需要顺序扫描的时候会读取其中的数据块,包括三种Block:Data Block,Leaf Index Block,Bloom Block
- No-scanned block section:在顺序扫描时不会读取,主要包括:meta block,intermediate level data index block
- load-on-open-section:在RS启动时会加载到内存中,包括:FileInfo,Bloom filter block,data block index,meta block index
- Trailer:包含了HFile的基本信息,各部分的偏移量,寻址信息
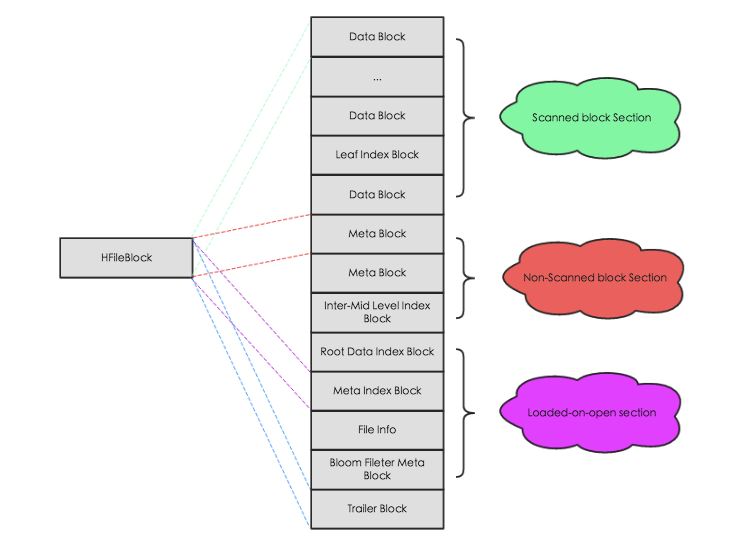
可以看见各个区域都是由大小相同的block构成的(默认64k,可以指定),block拥有相同的数据结构,因此统一抽象为HFileBlock。其中又包含带有checksum和不带checksum的。
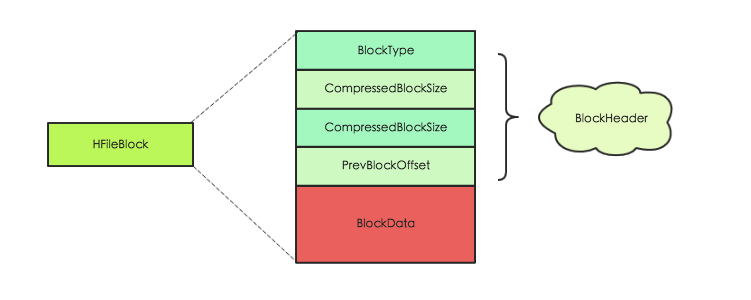
HFileBlock分为header和data部分,header存储该block的元数据信息,主要是BlockType标注了是哪一种Block。data部分各不相同。
8中BlockType
| BlockType | 介绍 |
| ———————— | ———————————————– |
| Trailer Block | 记录HFile的基本信息,各部分的偏移量寻址信息 |
| meta Block | 记录布隆过滤器元数据信息 |
| data Block | 存储用户的kv |
| root index | datablock的根索引以metaBloc和Bloom Filter的索引 |
| Intermediate Level Index | dataBlock 中的二级索引 |
| Leaf Level Index | dataBlock的三级索引,也就是叶子节点 |
| Bloom meta Block | Bloom的相关元数据 |
| Bloom Block | Bloom的相关数据 |
HFile在读取的时候首先会解析Trailer Block并加载到内存,然后再进一步加载LoadOnOpen区的数据。
HFile 索引
数据在memStore中使用的是map+跳跃表,保证有序和读写性能。在磁盘上HFile上,索引是一颗多叉树,最高三层索引。
宕机恢复
Master宕机恢复
master的压力较低,因此宕机情况比较少。
故障恢复原理:一般至少存在两个master,并且以热备的方式实现高可用。master会在zk上注册一个临时节点,只有一个master能够成为active,其他成为backup-master,但是依旧会关注active master,当active宕机时,它们能够立即得到通知,并且再次竞争成为active节点
RS宕机
常见的宕机原因:
- full gc导致超时
- hdfs异常
- 机器宕机
- hbase bug
故障恢复原理:
- 检查故障,通过zk的心跳实现:设置合理的timeout
- 切分为持久化数据的HLog,因为回放log是按照Region为单位
- master分配宕机的RS上的Region给其他RS
- 回放HLog
- 对外提供服务
快照
snapshot并没有真正的复制数据,而是存储了当前需要复制的文件的元数据,可以通过这一系列元数据找到复制时的文件。
那么当源文件删除或者合并消失了呢,是不是就找不到了。当compaction或者delete 表的时候,会将原文件复制到archive目录下。
shell 操作:
- 为表’sourceTable’打一个快照’snapshotName’:
snapshot 'sourceTable', ‘snapshotName' - 恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失。需要注意的是原表需要先disable掉,才能执行restore_snapshot操作:
restore_snapshot ‘snapshotName' - 根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成。
clone_snapshot 'snapshotName', ‘tableName'
zk上存储的数据
zk上存储的数据,通过ls /habase查看1
2
3[zk: localhost:2181(CONNECTED) 24] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, master-maintenance, online-snapshot, switch, master, running, draining, namespace, hbaseid, table]
[zk: localhost:2181(CONNECTED) 25]
- meta-region-server:meta表所在的rs的地址
- rs:rs的信息
- splitWAL:用于故障恢复时,切割WAL时使用
- backup-master:备份master节点,可以有多个
- table-lock:用来实现分布式锁
- flush-table-proc
- master-maintenance:
- online-snapshot:用来实现在线快照的功能,每个Region都执行快照。master下达命令,RegionServer返回结果都是通过该节点完成
- switch:
- master:master节点
- running:
- draining:
- namespace:所有的namespace
- habaseid:
- table:所有表的信息
hbase在hdfs上的存储布局
hbase在hdfs上的存储布局1
2
3
4
5
6
7
8
9
10
11
12
13drwxr-xr-x - hadoop supergroup 0 2019-11-04 20:54 /hbase/.hbase-snapshot
drwxr-xr-x - hadoop supergroup 0 2019-10-31 14:25 /hbase/.hbck
drwxr-xr-x - hadoop supergroup 0 2019-11-13 15:53 /hbase/.tmp
drwxr-xr-x - hadoop supergroup 0 2019-11-13 15:53 /hbase/MasterProcWALs
drwxr-xr-x - hadoop supergroup 0 2019-11-13 15:53 /hbase/WALs
drwxr-xr-x - hadoop supergroup 0 2019-11-04 11:31 /hbase/archive
drwxr-xr-x - hadoop supergroup 0 2019-10-31 14:25 /hbase/corrupt
drwxr-xr-x - hadoop supergroup 0 2019-11-01 15:32 /hbase/data
-rw-r--r-- 1 hadoop supergroup 42 2019-10-31 14:25 /hbase/hbase.id
-rw-r--r-- 1 hadoop supergroup 7 2019-10-31 14:25 /hbase/hbase.version
drwxr-xr-x - hadoop supergroup 0 2019-10-31 14:25 /hbase/mobdir
drwxr-xr-x - hadoop supergroup 0 2019-11-13 16:13 /hbase/oldWALs
drwx--x--x - hadoop supergroup 0 2019-10-31 14:25 /hbase/staging
- .hbase-snapshot:执行snapshot后,相关的元数据文件存储在该目录
- .tmp:用于表的创建和删除操作,创建是先在此目录创建,成功后在转移到实际的目录
- .hbck
- MasterProcWALs:用于存储master procedure过程中的wal文件,wal文件可以用来在宕机等情况时进行回滚
- WALs:wal文件
- archive:文档归档目录
- 删除HFile时,将待删除的文件放入此目录
- 进行snapshot或者升级时使用
- Compaction时,将旧HFile移动到此目录
- corrupt:存储损坏的HLog或者HFile
- data:存储集群中所有Region的HFile数据,
/hbase/data/命名空间/表名/Region名称/列簇名/HFile文件名;表描述文件等等。 - 集群创建时创建的唯一id
- hbase.version:版本
- oldWALs:WAL归档目录,确认数据从memstore中flush到磁盘后,将WAL文件移动到此
二级索引
给定rowkey查询是很快的,但是正是由于这种设计,导致了HBase本身没有实现二级索引,但是可以自己实现:
全局索引
新建一张表:二级索引=>rowkey
- 这种设计必须要保证表之间的事务,但是HBase只有行之间的事务,所以需要手动实现。
- 写数据的时候要更新二级索引,因此必定会降低吞吐量,写多读少的时候更是得不偿失。
- 在读多写少的时候根据二级索引查效率较高
本地索引
本地索引的策略是将索引存储在一个Region中而不是新建表。
比如原表是{rowkey=id,name,class,age,g_id},现在将name设置为二级索引,那么多插入一行{rowkey=(id,name),class,age,g_id},
- 这种设计适合写多读少的情况
- 查询的时候回扫描rowkey,效率不如全局索引,但是写的逻辑简单
参考
- http://hbasefly.com/
- https://hbase.apache.org/book.html
- 《hbase原理与实践》,作者:胡争,范欣欣